ChessCoach
– Chris ButnerA neural network-based chess engine capable of natural language commentary
Development process
Introduction
The combination of large, talented, corporate-backed research teams and furtive publishing creates a "competitive moat" that others must cross when replicating and extending results. Developing software and gathering data to catch up to existing results can be complex, especially when high performance systems or specialized applications are required, and when details are missing or ambiguously specified. Perhaps more importantly, failed ideas are usually not presented, so others must wade through the same initially promising layers of low and medium-hanging fruit before reaching truly new idea space.
Community projects with public discussions and work tracking provide a good counterexample. I would like to take a similar approach here by listing experiments, bugs, failures, and ideas for future work, in the hope that I can save others time or frustration. Technical documentation, code and data are also available.
Learnings
It was enlightening to discover just how much time is required on the research side trying many ideas before finally finding one that works. Reinforcement learning makes this especially time consuming and expensive because of the raw computation required for end-to-end experiments. Improving a process can require running it many times. It was naïve of me to try to speed up training when initially lacking the resources to complete even a quarter of it.
The contrast between machine learning systems and general software engineering also became very clear when validating behavior and results. You can usually look at a partially developed website or application and say, "this thing is working correctly", or "these three things are broken". With ChessCoach, there was often not a hard, expected result from components such as neural network evaluations, training processes, and search logic. Results can be underwhelming because more training is needed, or because other components need to catch up, or because of a bug. This is even more of a problem with fewer eyes on the project. I underestimated the subtlety of bugs that could emerge and the strict validation necessary to maintain confidence, and trust in additional experiments.
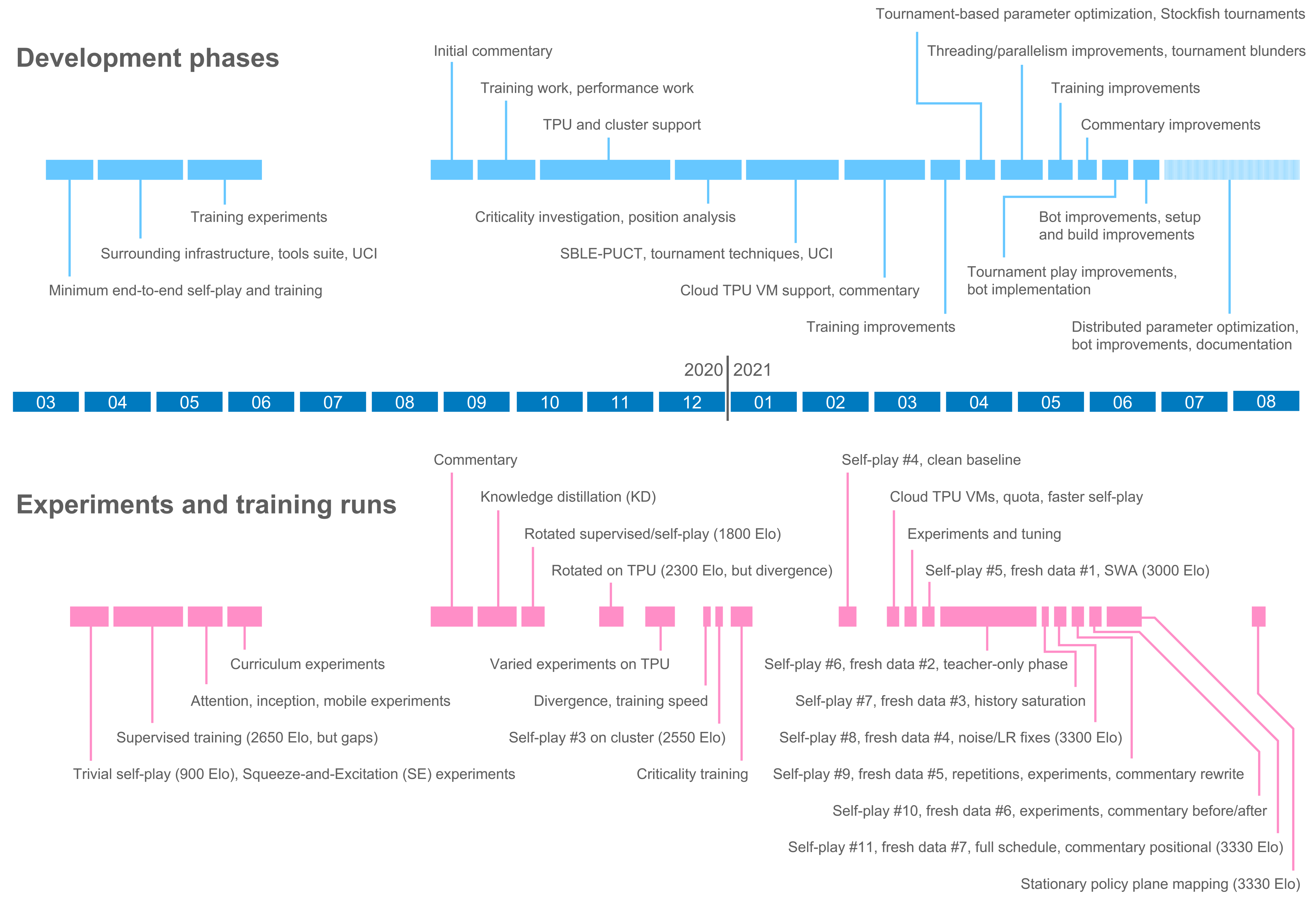
Timeline
I started preparation in March 2020. Beyond reading some articles, watching the AlphaGo match vs. Lee Se-dol, and taking an undergraduate subject covering MNIST handwriting recognition years ago, the machine learning side was going to be new. Research papers were extremely useful, spanning earlier neural network-based engines, autoencoders, commentary, criticality, introspection, and the AlphaGo family. I highly recommend the book, Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow (Géron, 2019). Some online courses seemed valuable but were a little too low-level and slow-going for the pace I was aiming for.
In mid-March 2020, I started development, using the Zeta36/chess-alpha-zero project (Zeta36, 2017) as a reference for TensorFlow 2 (Keras) model code, and the AlphaZero pseudocode (Silver et al., 2018) as a reference for self-play and training code. A little over a year of development time was required, running experiments and programming in parallel. Not much code was needed in the end. Most of the time was spent discovering (most likely rediscovering) what works and what does not, and scaling self-play infrastructure up and out. Work tracking was via TODO.txt, and I found that keeping a detailed development journal was also invaluable.
Major bugs
Throughout most of the project, nowhere near enough computational power and data were available for ChessCoach to progress meaningfully. It was not always clear whether it was working correctly but needed more training, or should be working better but had a bug. This meant that some particularly egregious bugs existed for long periods, even while the engine grew much stronger than I had initially planned.

Failures
Neural network architecture
Many different neural network architectures and parameterizations were tried in the hope of improving training and inference speed on consumer GPUs without significantly reducing comprehension. Unfortunately, only Inception-based architectures matched the baseline performance during supervised training, but with higher complexity. Attention-based architectures were usually slower and no better in quality. While aiming to be more efficient, mobile-based architectures ended up less so because of their lower memory efficiency, limiting batch sizes on limited consumer GPU memory.
Neural network architecture failures:
- 2D relative self-attention
- Attention-augmented convolutional networks
- ShuffleNet V2
- Inception with residuals, with and without separable convolutions, with and without attention
- Shuffleception
Training
Some training experiments simply failed to produce results. Others were more dangerous, providing short-term benefits in training convergence, but ending up neutral or harmful as the schedule reached 100,000 AlphaZero steps and beyond. This is something to be wary of in partial replications of AlphaZero-style reinforcement learning.
Some techniques that help in Go appear to hurt convergence in chess, either because of flipped perspective between moves, or tactical non-smoothness.
I was surprised to see no benefit from Squeeze-and-Excitation-style techniques after three attempts throughout the project, in contrast to Lc0. It may have been flawed implementation or parameterization on my part, or the non-stationary policy plane mappings in place until 2021/08/08.
The concept of trained criticality morphed into training-free SBLE-PUCT and other tournament play techniques.
Training failures:
- Squeeze-and-Excitation, KataGo pooling, and hybrids (no benefit)
- Fixup Initialization (seemed to prevent learning rate decreases; hints of instability)
- Curriculum learning: last-N moves, game start and biased sampling (disastrous)
- Data augmentation: rotating/mixing supervised and self-play data (eventually harmful)
- Auxiliary training targets: reply policy (eventually harmful)
- Forced playouts and policy targeting pruning (inconclusive; prior sharpening worries; some convergence instability without the pruning, once exploration noise was fixed)
- Trained criticality (too difficult to statistically classify without chicken-and-egg problems; too difficult to train stably; too difficult to propagate at search time from root outwards)
- Gradient accumulation (should help single-GPU achieve gradient smoothness and higher learning rate of multi-GPU/TPU, but two different implementation approaches hung TensorFlow; Model.fit() hangs were fixed in 2.4.0, so this may be better now)
- 15% auxiliary-style Syzygy probing during self-play (policy divergence)
- 5% auxiliary-style 10k deep simulations during self-play (policy divergence)
- Even (non-decaying) SWA at the end of training over many checkpoints (sacrificed too much certainty and endgame knowledge; commentary more vague; better suited to many epochs over stationary datasets; possibly still an improvement with fewer checkpoints)
Self-play and tournament play
Most self-play and tournament play failures centered on child selection during PUCT and simply showed no benefit. However, evaluation is quite sensitive to specific implementation and parameterization, and I believe that some of these ideas could work with more time and effort.
Before the network was fully trained, manually investigating individual Arasan21 positions was helpful, with successful techniques such as SBLE-PUCT able to redirect "wasted" simulations into broader exploration. Once policies were more accurate, it became more beneficial to manually investigate tournament blunders against Stockfish 13, discovering more varied problems and applying more targeted solutions.
Self-play and tournament play failures:
- CPU-to-GPU prediction multiplexing (competed with prediction freshness; may require C++ API)
- Stockfish valuation blending (eventually harmful)
- Regret-pruning
- Unpropagated value catch-up
- Macro-minimax, micro-minimax and last-value experiments
- Value standard error
- Killer heuristic, Stockfish-style, with multi-FPU-weight
- RAVE
- Prior squish, clip and decay
- Virtual loss only for selection checking, not backpropagation checking
- Sub-tree flood protection
- Exponential cyclic elimination for unbudgeted searches
Future work
Although I have no current plans for further development, it may be helpful to list ideas I was considering as part of the original scope.
-
Playing strength
- Improvements for all-winning/all-losing/all-drawing value-delta-versus-exploration, including better tablebase/PUCT integration (for example, PUCT leader debounce)
- Finish-fast utility score to encourage progress
- Contempt
-
Performance
- TensorFlow C++ API
- TensorRT and/or mixed precision
- TensorFlow profiling and architecture-specific optimizations
- PUCT vectorization
- Reduced node size
- Hard elimination, pruning sub-trees during search
-
Training
- Larger chunks (without hurting self-play worker and training turnaround) or BigTable
- TPU pod support for training
- Gradient accumulation on GPU
- Fast-SWA
- Playout cap randomization
- Game branching, seeking higher blunder/imbalance blend, with clipped result attribution
- Draw avoidance in the feedback cycle
- Knowledge distillation for regression (Saputra, de Gusmão, Almalioglu, Markham & Trigoni, 2019)
- Data augmentation
-
UCI
- MultiPV
- Ponder (bot uses custom implementation)
-
Commentary
- Varying sampling diversity based on token/phrase information entropy, with global evaluation and/or backtracking (for example, square/piece vs. connective)
- Perceiver (Jaegle et al., 2021)
-
Debug GUI
- Invert UCI/GUI relationship
- Browse EPDs
- Set up positions
- Control searches
- Visual clarity
- Information layout
- WebSocket reconnect